Modern Processors
Every Nomad node has a Central Processing Unit (CPU) providing the computational power needed for running operating system processes. Nomad uses the CPU to run tasks defined by the Nomad job submitter. For Nomad to know which nodes have sufficient capacity for running a given task, each node in the cluster is fingerprinted to gather information about the performance characteristics of its CPU. The two metrics associated with each Nomad node with regard to CPU performance are its bandwidth (how much it can compute) and the number of cores.
Modern CPUs may contain heterogeneous core types. Apple introduced the M1 CPU in 2020 which contains both performance (P-Core) and efficiency (E-Core) types. Each core type operates at a different base frequency. Intel introduced a similar topology in its Raptor Lake chips in 2022. When fingerprinting the characteristics of a CPU Nomad is capable of taking these advanced CPU topologies into account.

Calculating CPU Resources
The total CPU bandwidth of a Nomad node is the sum of the product between the frequency of each core type and the total number of cores of that type in the CPU.
The total number of cores is computed by summing the number of P-Cores and the number of E-Cores.
Nomad does not distinguish between logical and physical CPU cores. One of the defining differences between the P-Core and E-Core types is that the E-Cores do not support hyperthreading, whereas P-Cores do. As such a single physical P-Core is presented as 2 logical cores, and a single E-Core is presented as 1 logical core.
The example below is from a Nomad node with an Intel i9-13900 CPU. It is made up of mixed core types, with a P-Core base frequency of 2 GHz and an E-Core base frequency of 1.5 GHz.
These characteristics are reflected in the cpu.frequency.performance and
cpu.frequency.efficiency node attributes respectively.
Reserving CPU Resources
In the fingerprinted node attributes, cpu.totalcompute indicates the total
amount of CPU bandwidth the processor is capable of delivering. In some cases it
may be beneficial to reserve some amount of a node's CPU resources for use by
the operating system and other non-Nomad processes. This can be done in client
configuration.
The amount of reserved CPU can be specified in bandwidth via cpu.
Or as a specific set of cores on which to disallow the scheduling of Nomad
tasks. This capability is available on Linux systems only.
When the CPU is constrained by one of the above configurations, the node
attribute cpu.usablecompute indicates the total amount of CPU bandwdith
available for scheduling of Nomad tasks.
Allocating CPU Resources
When scheduling jobs, a Task must specify how much CPU resource should be
allocated on its behalf. This can be done in terms of bandwidth in MHz with the
cpu attribute. This MHz value is translated directly into cpushares on
Linux systems.
Note that the isolation mechansim around CPU resources is dependent on each task driver and its configuration. The standard behavior is that Nomad ensures a task has access to at least as much of its allocated CPU bandwidth. In which case if a node has idle CPU capacity, a task may use additional CPU resources. Some task drivers enable limiting a task to use only the amount of bandwidth allocated to the task, described in the CPU Hard Limits section below.
On Linux systems, Nomad supports reserving whole CPU cores specifically for a task. No task will be allowed to run on a CPU core reserved for another task.
Nomad Enterprise supports NUMA aware scheduling, which enables operators to more finely control which CPU cores may be reserved for tasks.
CPU Hard Limits
Some task drivers support the configuration option cpu_hard_limit. If enabled
this option restricts tasks from bursting above their CPU limit even when there
is idle capacity on the node. The tradeoff is consistency versus utilization.
A task with too few CPU resources may operate fine until another task is placed
on the node causing a reduction in available CPU bandwidth, which could cause
distruption for the underprovisioned task.
CPU Environment Variables
To help tasks understand the resources available to them, Nomad sets the following environment variables in their runtime environment.
NOMAD_CPU_LIMIT- The amount of CPU bandwidth allocated on behalf of the task.NOMAD_CPU_CORES- The set of cores in [cpuset][] notation reserved for the task. This value is only set if `resources.cores` is configured.
NUMA
Nomad clients are commonly provisioned on real hardware in an on-premise
environment or in the cloud on large .metal instance types. In either case it
is likely the underlying server is designed around a NUMA topology.
Servers that contain multiple CPU sockets or multiple RAM banks per CPU socket
are characterized by the non-uniform access times involved in accessing system
memory.
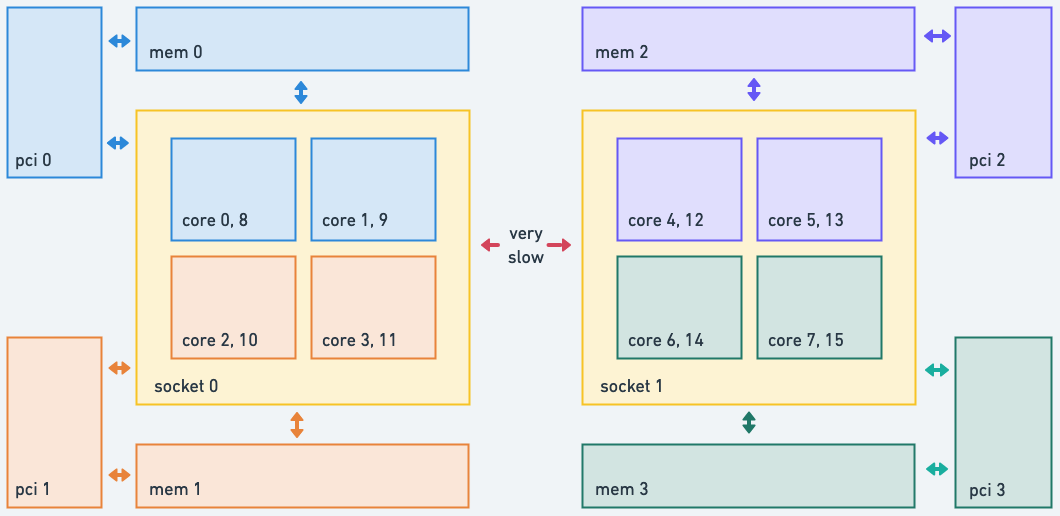
The simplified example machine above has the following topology
- 2 physical CPU sockets
- 4 system memory banks, 2 per socket
- 8 physical cpu cores (4 per socket)
- 2 logical cpu cores per physical core
- 4 PCI devices, 1 per memory bank
Optimizing performance
Operating system processes take longer to access memory across a NUMA boundary.
Using the example above if a task is scheduled on Core 0, accessing memory in Mem 1 might take 20% longer than accessing memory in Mem 0, and accessing memory in Mem 2 might take 300% longer.
The extreme differences are due to various physical hardware limitations. A core accessing memory in its own NUMA node is optimal. Programs which perform a high throughput of reads or writes to/from system memory will have their performance substantially hindered by not optimizing their spatial locality iwth regard to the systems NUMA topology.
SLIT tables
Modern machines will define System Locality Distance Information (SLIT) tables in their firmware. These tables are understood and made referenceable by the Linux kernel. There are two key pieces of information provided by SLIT tables:
- Which CPU cores belong to which NUMA nodes
- The penalty incurred for accessing each NUMA node from a core in every other NUMA node
The lscpu command can be used to describe the Core associativity on a machine.
For example on an r6a.metal EC2 instance:
And the associated performance degradations are available via numactl:
These SLIT table "node distance" values are presented as approximate relative ratios. The value of 10 represents an optimal situation where a memory access is occuring from a CPU that is part of the same NUMA node. A value of 20 would indicate a 200% performance degradation, 30 for 300%, etc.
Node Attributes
Nomad clients will fingerprint the machine's NUMA topology and export the core associativity as node attributes. This data can provide a Nomad operator a better understanding of when it might be useful to make use of NUMA aware scheduling for certain workloads.
NUMA aware scheduling Enterprise
Nomad Enterprise is capable of scheduling tasks in a way that is optimized for
the NUMA topology of a client node. A task may specify a numa block indicating
its NUMA optimization preference.
affinity Options
There are three supported affinity options: none, prefer, and require,
each with their own advantages and tradeoffs.
option none
In the none mode the Nomad scheduler leverages the apathy of jobs without
preference of NUMA affinity to help reduce core fragmentation within NUMA nodes.
It does so by bin-packing the core request of these jobs onto the NUMA nodes
with the fewest unused cores available.
The none mode is the default mode if the numa block is not specified.
option prefer
In the prefer mode the Nomad scheduler uses the hardware topology of a node
to calculate an optimized selection of available cores, but does not limit
those cores to come from a single NUMA node.
option require
In the require mode the Nomad scheduler uses the topology of each potential
client to find a set of available CPU cores that belong to the same NUMA node.
If no such set of cores can be found, that node is marked exhasusted for the
resource of numa-cores.